Nvidia, einer der führenden Anbieter von Grafikprozessoren (GPUs) und KI-Hardware, hat kürzlich zwei neue Supercomputer-GPUs angekündigt, die das Tempo beim KI-Supercomputing noch weiter beschleunigen sollen. Die neuen GPUs, B100 und X100 genannt, versprechen eine enorme Leistungssteigerung und ermöglichen es Forschern und Wissenschaftlern, noch anspruchsvollere KI-Algorithmen schneller und effizienter als je zuvor auszuführen.
Die B100 GPU ist die neueste Ergänzung von Nvidia’s vollem Angebot an GPUs für High-Performance Computing und Künstliche Intelligenz. Mit 8192 CUDA-Kernen und 320 Tensor-Kernen bietet die B100 eine unglaubliche Rechenleistung und ermöglicht es Forschern, Modelle zu trainieren und komplexe Berechnungen viel schneller durchzuführen. Zusätzlich unterstützt die GPU eine Speicherbandbreite von 1 TB/s, was eine noch schnellere Datenübertragung und -verarbeitung ermöglicht.
Die X100 GPU hingegen richtet sich speziell an Unternehmen und Supercomputer-Zentren, die große Mengen an Daten verarbeiten müssen. Mit 16384 CUDA-Kernen und 640 Tensor-Kernen bietet die X100 eine doppelt so hohe Rechenleistung wie die B100. Zusammen mit der Unterstützung einer Speicherbandbreite von 2 TB/s ermöglicht diese GPU eine noch schnellere Verarbeitung von KI-Algorithmen und eine nahezu Echtzeit-Analyse großer Datenmengen.
Beide GPUs werden auf Nvidias neuer Ampere-Architektur basieren, die eine verbesserte Energieeffizienz und Leistung bietet. Dies ermöglicht es Unternehmen und Organisationen, KI-Anwendungen mit höherem Durchsatz auszuführen, während die Stromversorgung und Kühlung optimiert werden. Dies ist besonders wichtig für den Einsatz in Supercomputer-Zentren, wo eine hohe Leistung und Energieeffizienz entscheidend sind.
Die Einführung der B100 und X100 GPUs markiert einen weiteren Meilenstein in der Entwicklung von Hardware für KI-Supercomputing. Mit diesen GPUs können Forscher und Wissenschaftler ihre KI-Algorithmen schneller trainieren, komplexe Berechnungen durchführen und Erkenntnisse aus großen Datenmengen gewinnen. Dies ermöglicht es ihnen, neue Lösungen für wichtige Herausforderungen in den Bereichen Gesundheit, Energie, Klimawandel und mehr zu finden.
Ein Beispiel dafür, wie die B100 und X100 GPUs eingesetzt werden können, ist die medizinische Bildgebung. Durch den Einsatz von KI-Algorithmen können Ärzte medizinische Bilder schneller und genauer analysieren. Mit den neuen GPUs können KI-Algorithmen in Echtzeit angewendet werden, was zu schnelleren Diagnosen und einem verbesserten Patientenoutcome führt.
Darüber hinaus können die GPUs auch in der Automobilindustrie eingesetzt werden, um autonomes Fahren weiter voranzutreiben. KI-Algorithmen sind entscheidend, um autonome Fahrzeuge sicher und effizient zu machen. Mit den neuen GPUs können Forscher und Ingenieure diese Algorithmen schneller trainieren und verbessern, was zu einer schnelleren Einführung von autonomen Fahrzeugen führen kann.
Die Einführung der B100 und X100 GPUs von Nvidia zeigt deutlich, dass das Tempo beim KI-Supercomputing weiter voranschreitet. Mit diesen GPUs können Forscher und Wissenschaftler noch komplexere Aufgaben bewältigen und schnellere Ergebnisse erzielen. Dies wird zu bahnbrechenden Fortschritten in vielen Bereichen führen, darunter Medizin, Automobilindustrie, Wettervorhersage, Klimaforschung und vieles mehr.
Insgesamt werden die B100 und X100 GPUs von Nvidia das KI-Supercomputing auf ein neues Niveau heben. Mit unglaublicher Rechenleistung, hoher Energieeffizienz und schneller Datenverarbeitung werden sie die Entwicklung von KI-Anwendungen und die Lösung komplexer Probleme beschleunigen. Dies ist ein weiterer Schritt in Richtung einer KI-gesteuerten Zukunft, in der maschinelles Lernen und Künstliche Intelligenz in verschiedenen Branchen weit verbreitet sein werden.
Nog geen twee jaar geleden kan Nvidia, vooral in het huidige ritme, GPU-microarchitectuur implementeren voor de ontwikkeling van AI-segmenten. Dit is een officiële hervorming van de Roadmap die nuttig zal zijn voor investeerders. Demnach stehen B100 noch 2025 en
De Tesla P100 was een grafische processor van Nvidia voor onderzoek met focus op het gebied van AI-supercomputing. Na 2016 volgt de Pascal Microarchitecture de Volta uit 2018 met de V100, vervolgens de Ampere uit 2025 met de A100 en de Hopper uit 2025 met de actieve eerste aanvragen H100, die de wereldwijde KI-Boom kan ondersteunen.
Nvidia zal de Tempo echter een nieuwe officiële Roadmap (PDF) blijven volgen en doorgaan met het huidige ritme. In deze op investeerders gerichte routekaart kunt u gebruik maken van de datacenterondersteuning en AI-supercomputing van Nvidia, evenals van consumentenproducten, die zullen profiteren van GeForce grafische kaarten.
GH200 is het eerste apparaat voor een hoger tempo
De Nvidia kan dezelfde snelheid gebruiken en zal blij zijn met de Grace Hopper Superchip. Door de combinatie van een Arm-basierter Grace CPU met Hopper GPU met de H200 kun je upgraden met een 141 GB HBM3e met 5 TB/s pro GPU en uitgerust worden met de GH200 Grace Hopper Superchip.
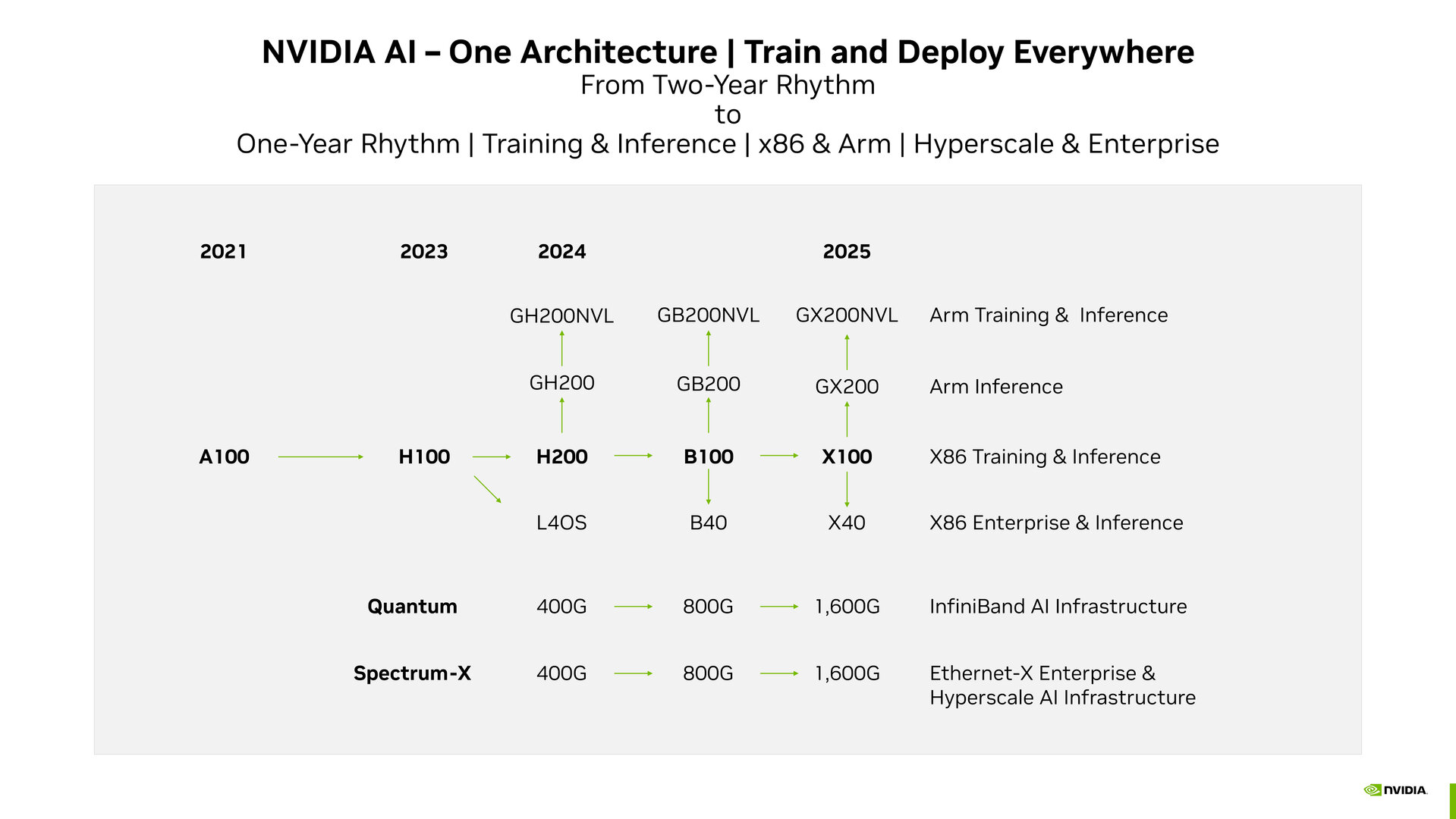
H200 is de drijvende kracht achter de pure Hopper-H100-GPU voor AI-training en inferentie op een X86-platform. Voor de storing in combinatie met de eigen Arm CPU de oplossing onder de namen GH200. Diese Lösungen sollen 2025 op de Markt kommen. Voor Multi-GPU systeemconfiguratie in het “Arm Training & Inference” plan heeft Nvidia namens GH200NVL een roadmap voor een oplossing. In de categorie “X86 Enterprise & Inference” is de August vorgestellte L40S gebaseerd op de Ada-Lovelace-architectuur voor het Omniversum. Zowel Quantum als Spectrum X bieden InfiniBand- en Ethernet-architecturen die door Nvidia worden ondersteund met 400 Gbit/s.
Blackwell komt volgend jaar
Voor de jaren betrokken bij de ontwikkeling en het potentieel voor de marktontwikkeling van het Blackwell-Mikroarchitektur erwartet. In het centrum bevindt zich een datacenteroplossing voor de grafische processor B100, die door de vorige Mikroarchitektur Ableitungen namens GB200 en GB200NVL werd geplant, evenals GPU’s, die werden gecombineerd met Arm-CPU. Voor het Omniversum staat de B40 in de Roadmap. De netwerkoplossingen zijn voldoende voor maximaal 800 Gbit/s.
1,6 Tbit/s met geïnstalleerd netwerk
De resultaten zullen in 2025 worden gepubliceerd met dezelfde opbouw grafische processor. In het netwerk zal Nvidia de bandbreedte van 1,6 Tbit/s en enkele abermals verbeteren.